DA (and Publication)
This page is heavily based on the Rollup and Data Ramblings documents. As for that, we highly recommend reading this very nice post written by Jon Charbonneau.
- Data Availability: The data is available to anyone right now
- Data Publication: The data was available for a period when it was published.
Essentially Data Publication Data Availability, since if it is available, it must also have been published. This difference might be small but becomes important in a few moments.
Progressing the state of the validating light node requires that we can convince it that the data was published - as it needs to compute the public inputs for the proof. The exact method of computing these public inputs can vary depending on the data layer, but generally, it could be by providing the data directly or by using data availability sampling or a data availability committee.
The exact mechanism greatly impacts the security and cost of the system, and will be discussed in the following sections. Before that we need to get some definitions in place.
Definitions
Security is often used quite in an unspecific manner, "good" security etc, without specifying what security is. From distributed systems, the security of a protocol or system is defined by:
- Liveness: Eventually something good will happen.
- Safety: Nothing bad will happen.
In the context of blockchain, this security is defined by the confirmation rule, while this can be chosen individually by the user, our validating light node (L1 bridge) can be seen as a user, after all, it's "just" another node. For the case of a validity proof based blockchain, a good confirmation rule should satisfy the following sub-properties (inspired by Sreeram's framing):
- Liveness:
- Data Availability - The chain data must be available for anyone to reconstruct the state and build blocks
- Ledger Growth - New blocks will be appended to the ledger
- Censorship Resistance - Honest transactions that are willing to pay will be included if the chain progresses.
- Safety:
- Re-org Resistance - Confirmed transactions won't be reverted
- Data Publication - The state changes of the block is published for validation check
- State Validity - State changes along with validity proof allow anyone to check that new state ROOTS are correct.
Notice, that safety relies on data publication rather than availability. This might sound strange, but since the validity proof can prove that the state transition function was followed and what changes were made, we strictly don't need the entire state to be available for safety.
With this out the way, we will later be able to reason about the choice of data storage/publication solutions. But before we dive into that, let us take a higher level look at Aztec to get a understanding of our requirements.
In particular, we will be looking at what is required to give observers (nodes) different guarantees similar to what Jon did in his post. This can be useful to get an idea around what we can do for data publication and availability later.
Rollup 101
A rollup is broadly speaking a blockchain that put its blocks on some other chain (the host) to make them available to its nodes. Most rollups have a contract on this host blockchain which validates its state transitions (through fault proofs or validity proofs) taking the role of a full-validating light-node, increasing the accessibility of running a node on the rollup chain, making any host chain node indirectly validate its state.
With its state being validated by the host chain, the security properties can eventually be enforced by the host-chain if the rollup chain itself is not progressing. Bluntly, the rollup is renting security from the host. The essential difference between an L1 and a rollup then comes down to who are required for block production (liveness) and to convince the validating light-node (security). For the L1 it is the nodes of the L1, and for the Rollup the nodes of its host (eventually). This in practice means that we can get some better properties for how easy it is to get sufficient assurance that no trickery is happening.
| Security | Accessibility | |
|---|---|---|
| Full node | 😃 | 😦 |
| Full-verifier light node (L1 state transitioner) | 😃 | 😃 |
With that out the way, we can draw out a model of the rollup as a two-chain system, what Jon calls the dynamically available ledger and the finalized prefix ledger.
The point where we jump from one to the other depends on the confirmation rules applied.
In Ethereum the dynamically available chain follows the LMD-ghost fork choice rule and is the one block builders are building on top of.
Eventually consensus forms and blocks from the dynamic chain gets included in the finalized chain (Gasper).
Below image is from Bridging and Finality: Ethereum.

In rollup land, the available chain will often live outside the host where it is built upon before blocks make their way onto the host DA and later get finalized by the validating light node that lives on the host as a smart contract.
Depending on the rollup mechanism, rollup full nodes will be able to finalize their own view of the chain as soon as data is available on the host.
Since the rollup cannot add invalid state transitions to the finalized chain due to the validating light node on the host, rollups can be built with or without a separate consensus mechanism for security.
One of the places where the existence of consensus make a difference for the rollup chain is how far you can build ahead, and who can do it.
Consensus
For a consensus based rollup you can run LMD-Ghost similarly to Ethereum, new blocks are built like Ethereum, and then eventually reach the host chain where the light client should also validate the consensus rules before progressing state. In this world, you have a probability of re-orgs trending down as blocks are built upon while getting closer to the finalization. Users can then rely on their own confirmation rules to decide when they deem their transaction confirmed. You could say that the transactions are pre-confirmed until they convince the validating light-client on the host.
No-consensus
If there is no explicit consensus for the Rollup, staking can still be utilized for leader selection, picking a distinct sequencer which will have a period to propose a block and convince the validating light-client. The user can as earlier define his own confirmation rules and could decide that if the sequencer acknowledges his transaction, then he sees it as confirmed. This has weaker guarantees than the consensus-based approach as the sequencer could be malicious and not uphold his part of the deal. Nevertheless, the user could always do an out-of-protocol agreement with the sequencer, where the sequencer guarantees that he will include the transaction or the user will be able to slash him and get compensated.
Fernet lives in this category if you have a single sequencer active from the proposal to proof inclusion stage.
Common for both consensus and no-consensus rollups is that the user can decide when he deems his transaction confirmed. If the user is not satisfied with the guarantee provided by the sequencer, he can always wait for the block to be included in the host chain and get the guarantee from the host chain consensus rules.
Data Availability and Publication
As alluded to earlier, we belong to the school of thought that Data Availability and Publication are different things. Generally, what is often referred to as Data Availability is merely Data Publication, e.g., whether or not the data have been published somewhere. For data published on Ethereum you will currently have no issues getting a hold of the data because there are many full nodes and they behave nicely, but they are not guaranteed to continue doing so. New nodes are essentially bootstrapped by other friendly nodes.
With that out the way, it would be prudent to elaborate on our definition from earlier:
- Data Availability: The data is available to anyone right now
- Data Publication: The data was available for a period when it was published.
With this split, we can map the methods of which we can include data for our rollup. Below we have included only systems that are live or close to live where we have good ideas around the throughput and latency of the data. The latency is based on using Ethereum L1 as the home of the validating light node, and will therefore be the latency between point in time when data is included on the data layer until a point when statements about the data can be included in the host chain.
| Method | Publication | Availability | Quantity | Latency | Description |
|---|---|---|---|---|---|
| calldata | Eth L1 | Eth L1 | None | Part of the transaction payload required to execute history, if you can sync an Ethereum node from zero, this is available. Essentially, if Ethereum lives this is available. Have to compete against everything on Ethereum for blockspace. | |
| blobs | Eth L1 | benevolent Eth L1 super full-nodes | x | None | New blob data, will be published but only commitments available from the execution environment. Content can be discarded later and doesn't have to be stored forever. Practically a "committee" of whoever wants can keep it, and you rely on someone from this set providing the data to you. |
| ^^ | None | target of 3 blobs of size 4096 fields (380,928 bytes per block) | |||
| ^^ | None | target of 64 blobs of size 4096 fields (8,126,464 bytes per block) | |||
| Celestia | Celestia + Blobstream bridge | Celestia Full Storage Nodes | ~100 mins | 2MB blocks. Can be used in proof after relay happens, with latency improvements expected. |
Data Layer outside host
When using a data layer that is not the host chain, cost (and safety guarantees) are reduced, and we rely on some "bridge" to tell the host chain about the data. This must happen before our validating light node can progress the block. Therefore the block must be published, and the host must know about it before the host can use it as input to block validation.
This influences how blocks can practically be built, since short "cycles" of publishing and then including blocks might not be possible for bridges with significant delay. This means that a suitable data layer has both sufficient data throughput but also low (enough) latency at the bridge level.
Briefly the concerns we must have for any supported data layer that is outside the host chain is:
- What are the security assumptions of the data layer itself
- What are the security assumptions of the bridge
- What is the expected data throughput (kb/s)
- What is the expected delay (mins) of the bridge
Celestia
Celestia mainnet is starting with a limit of 2 mb/block with 12 second blocks supporting ~166 KB/s.
They are working on increasing this to 8 mb/block.
As Celestia has just recently launched, it is unclear how much competition there will be for the data throughput, and thereby how much we could expect to get a hold of. Since the security assumptions differ greatly from the host chain (Ethereum) few L2s have been built on top of it yet, and the demand is to be gauged in the future.
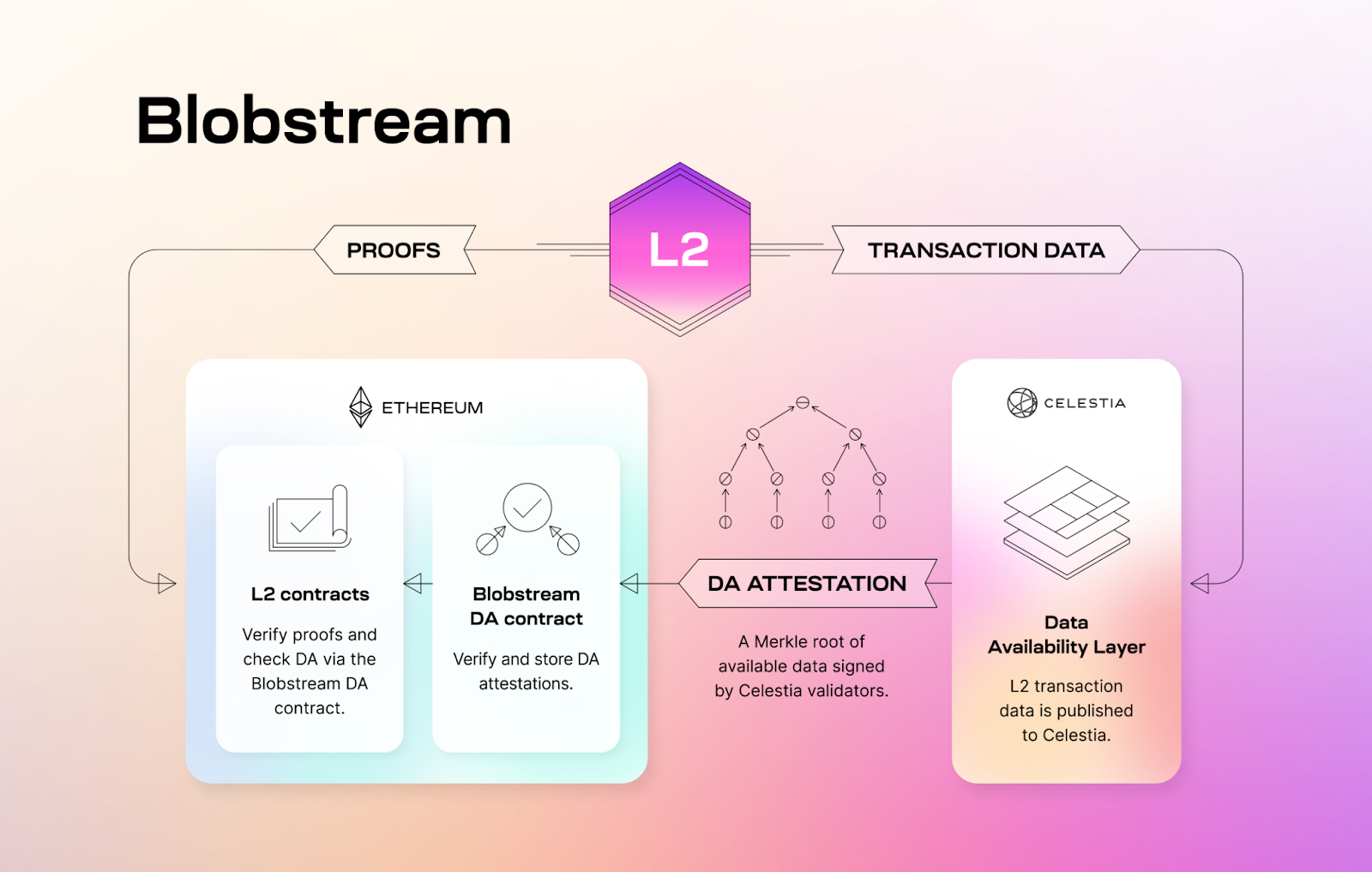
Beyond the pure data throughput, we also need Ethereum L1 to know that the data was made available on Celestia. This will require the blobstream (formerly the quantum gravity bridge) to relay data roots that the rollup contract can process. This is currently done approximately every 100 minutes. Note however, that a separate blobstream is being build by Succinct labs (live on goerli) which should make relays cheaper and more frequent.
Neat structure of what the availability oracles will look like created by the Celestia team:
Espresso
Espresso is not yet live, so the following section is very much in the air, it might be that the practical numbers will change when it is live.
Our knowledge of hotshot is limited here - keeping commentary limited until more educated in this matter.
From their benchmarks, it seems like the system can support 25-30MB/s of throughput by using small committees of 10 nodes. The throughput further is impacted by the size of the node-set from where the committee is picked.
While the committee is small, it seems like they can ensure honesty through the other nodes. But the nodes active here might need a lot of bandwidth to handle both DA Proposals and VID chunks.
It is not fully clear how often blocks would be relayed to the hotshot contract for consumption by our rollup, but the team says it should be frequent. Cost is estimated to be ~400K gas.
Aztec-specific Data
As part of figuring out the data throughput requirements, we need to know what data we need to publish. In Aztec we have a bunch of data with varying importance; some being important to everyone and some being important to someone.
The things that are important to everyone are the things that we have directly in state, meaning the:
- leaves of the note hash tree
- nullifiers
- public state leafs
- contracts
- L1 -> L2
- L2 -> L1
Some of these can be moved around between layers, and others are hard-linked to live on the host. For one, moving the cross-chain message L1 -> L2 and L2 -> L1 anywhere else than the host is fighting an up-hill battle. Also, beware that the state for L2 -> L1 messages is split between the data layers, as the messages don't strictly need to be available from the L2 itself, but must be for consumption on L1.
We need to know what these things are to be able to progress the state. Without having the state, we don't know how the output of a state transition should look and cannot prove it.
Beyond the above data that is important to everyone, we also have data that is important to someone. These are encrypted and unencrypted logs. Knowing the historic logs is not required to progress the chain, but they are important for the users to ensure that they learn about their notes etc.
A few transaction examples based on our E2E tests have the following data footprints. We will need a few more bytes to specify the sizes of these lists but it will land us in the right ball park.
These were made back in August 2023 and are a bit outdated. They should be updated to also include more complex transactions.
Tx ((Everyone, Someone) bytes).
Tx ((192, 1005) bytes): comms=4, nulls=2, pubs=0, l2_to_l1=0, e_logs=988, u_logs=17
Tx ((672, 3980) bytes): comms=16, nulls=5, pubs=0, l2_to_l1=0, e_logs=3932, u_logs=48
Tx ((480, 3980) bytes): comms=13, nulls=2, pubs=0, l2_to_l1=0, e_logs=3932, u_logs=48
Tx ((640, 528) bytes): comms=4, nulls=16, pubs=0, l2_to_l1=0, e_logs=508, u_logs=20
Tx ((64, 268) bytes): comms=1, nulls=1, pubs=0, l2_to_l1=0, e_logs=256, u_logs=12
Tx ((128, 512) bytes): comms=2, nulls=2, pubs=0, l2_to_l1=0, e_logs=500, u_logs=12
Tx ((96, 36) bytes): comms=0, nulls=1, pubs=1, l2_to_l1=0, e_logs=8, u_logs=28
Tx ((128, 20) bytes): comms=0, nulls=2, pubs=1, l2_to_l1=0, e_logs=8, u_logs=12
Tx ((128, 20) bytes): comms=1, nulls=1, pubs=1, l2_to_l1=0, e_logs=8, u_logs=12
Tx ((96, 268) bytes): comms=1, nulls=2, pubs=0, l2_to_l1=0, e_logs=256, u_logs=12
Tx ((224, 28) bytes): comms=1, nulls=2, pubs=2, l2_to_l1=0, e_logs=12, u_logs=16
Tx ((480, 288) bytes): comms=1, nulls=2, pubs=6, l2_to_l1=0, e_logs=260, u_logs=28
Tx ((544, 32) bytes): comms=0, nulls=1, pubs=8, l2_to_l1=0, e_logs=8, u_logs=24
Tx ((480, 40) bytes): comms=0, nulls=1, pubs=7, l2_to_l1=0, e_logs=12, u_logs=28
Average bytes, (rounded up):
Everyone: 311 bytes
Someone: 787 bytes
Total: 1098 bytes
For a more liberal estimation, lets suppose we emit 4 nullifiers, 4 new note hashes, and 4 public data writes instead per transaction.
Tx ((512, 1036) bytes): comms=4, nulls=4, pubs=4, l2_to_l1=0, e_logs=988, u_logs=48
Assuming that this is a decent guess, and we can estimate the data requirements at different transaction throughput.
Throughput Requirements
Using the values from just above for transaction data requirements, we can get a ball park estimate of what we can expect to require at different throughput levels.
| Throughput | Everyone | Someone | Total |
|---|---|---|---|
| 1 TPS | |||
| 10 TPS | |||
| 50 TPS | |||
| 100 TPS |
Assuming that we are getting of the blob-space or of the calldata and amortize to the Aztec available space.
For every throughput column, we insert 3 marks, for everyone, someone and the total; ✅✅✅ meaning that the throughput can be supported when publishing data for everyone, someone and the total. 💀💀💀 meaning that none of it can be supported.
| Space | Aztec Available | 1 TPS | 10 TPS | 50 TPS | 100 Tps |
|---|---|---|---|---|---|
| Calldata | ✅✅✅ | 💀💀💀 | 💀💀💀 | 💀💀💀 | |
| Eip-4844 | ✅✅✅ | 💀💀💀 | 💀💀💀 | 💀💀💀 | |
| 64 blob danksharding | ✅✅✅ | ✅✅✅ | ✅✅✅ | ✅✅💀 | |
| Celestia (2mb/12s blocks) | ✅✅✅ | ✅✅✅ | 💀💀💀 | 💀💀💀 | |
| Celestia (8mb/13s blocks) | ✅✅✅ | ✅✅✅ | ✅✅💀 | ✅💀💀 | |
| Espresso | Unclear but at least 1 mb per second | ✅✅✅ | ✅✅✅ | ✅✅✅ | ✅✅✅ |
Disclaimer: Remember that these fractions for available space are pulled out of thin air.
With these numbers at hand, we can get an estimate of our throughput in transactions based on our storage medium.
One or multiple data layers?
From the above estimations, it is unlikely that our data requirements can be met by using only data from the host chain. It is therefore to be considered whether data can be split across more than one data layer.
The main concerns when investigating if multiple layers should be supported simultaneously are:
- Composability: Applications should be able to integrate with one another seamlessly and synchronously. If this is not supported, they might as well be entirely separate deployments.
- Ossification: By ossification we mean changing the assumptions of the deployments, for example, if an application was deployed at a specific data layer, changing the layer underneath it would change the security assumptions. This is addressed through the Upgrade mechanism.
- Security: Applications that depend on multiple different data layers might rely on all its layers to work to progress its state. Mainly the different parts of the application might end up with different confirmation rules (as mentioned earlier) degrading it to the least secure possibly breaking the liveness of the application if one of the layers is not progressing.
The security aspect in particular can become a problem if users deploy accounts to a bad data layer for cost savings, and then cannot access their funds (or other assets) because that data layer is not available. This can be a problem, even though all the assets of the user lives on a still functional data layer.
Since the individual user burden is high with multi-layer approach, we discard it as a viable option, as the probability of user failure is too high.
Instead, the likely design, will be that an instance has a specific data layer, and that "upgrading" to a new instance allows for a new data layer by deploying an entire instance. This ensures that composability is ensured as everything lives on the same data layer. Ossification is possible hence the upgrade mechanism doesn't "destroy" the old instance. This means that applications can be built to reject upgrades if they believe the new data layer is not secure enough and simple continue using the old.
Privacy is Data Hungry - What choices do we really have?
With the target of 10 transactions per second at launch, in which the transactions are likely to be more complex than the simple ones estimated here, some of the options simply cannot satisfy our requirements.
For one, EIP-4844 is out of the picture, as it cannot support the data requirements for 10 TPS, neither for everyone or someone data.
At Danksharding with 64 blobs, we could theoretically support 50 tps, but will not be able to address both the data for everyone and someone. Additionally this is likely years in the making, and might not be something we can meaningfully count on to address our data needs.
With the current target, data cannot fit on the host, and we must work to integrate with external data layers. Of these, Celestia has the current best "out-the-box" solution, but Eigen-da and other alternatives are expected to come online in the future.
References
- https://dba.xyz/do-rollups-inherit-security/
- https://ethereum.org/en/roadmap/danksharding/
- https://eips.ethereum.org/EIPS/eip-4844
- https://github.com/ethereum/consensus-specs/blob/dev/specs/deneb/polynomial-commitments.md
- https://eth2book.info/capella/part2/consensus/lmd_ghost/
- https://eth2book.info/capella/part2/consensus/casper_ffg/
- https://notes.ethereum.org/cG-j3r7kRD6ChQyxjUdKkw
- https://forum.celestia.org/t/security-levels-for-data-availability-for-light-nodes/919
- https://ethresear.ch/t/peerdas-a-simpler-das-approach-using-battle-tested-p2p-components/16541
- https://jumpcrypto.com/writing/bridging-and-finality-ethereum/
- https://x.com/sreeramkannan/status/1683735050897207296
- https://blog.celestia.org/introducing-blobstream/