Indexed Merkle Tree (Nullifier Tree)
Prerequisites
This page assumes familiarity with:
- Merkle trees and membership proofs
- The UTXO model for private state
- Zero-knowledge proof concepts (circuits, constraints)
Overview
This page covers indexed merkle trees and how they improve nullifier tree performance in circuits, including:
- Why nullifier trees are necessary
- How indexed merkle trees work
- Membership exclusion proofs
- Batch insertions
- Tradeoffs
This content was presented to the Privacy + Scaling Explorations team at the Ethereum Foundation.
Primer on Nullifier Trees
Privacy in public blockchains requires a UTXO model. State is stored in encrypted UTXOs in merkle trees. Since updating state directly leaks information, we simulate updates by "destroying" old UTXOs and creating new ones, resulting in an append-only merkle tree.
A classic merkle tree:
To destroy state, a "nullifier" tree stores deterministic values linked to notes in the append-only tree. This is typically implemented as a sparse Merkle Tree.
A sparse merkle tree (not every leaf stores a value):
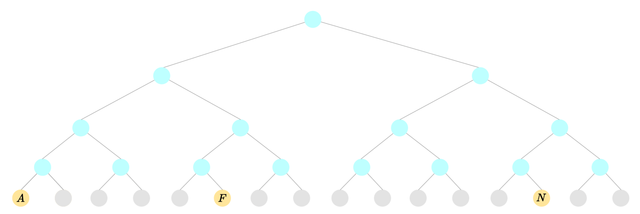
To spend or modify a note in the private state tree, you must create a nullifier and prove it does not already exist in the nullifier tree. Since nullifier trees are modeled as sparse merkle trees, non-membership checks are conceptually trivial.
Data is stored at the leaf index corresponding to its value. For example, in a sparse tree containing values, to prove non-membership of value :
- Prove via a merkle membership proof (value does not exist)
- Conversely, prove to show the item exists
Problems introduced by using Sparse Merkle Trees for Nullifier Trees
While sparse Merkle Trees offer a simple solution, they have significant drawbacks. A sparse nullifier tree must have an index for , which for the bn254 curve requires a depth of 254.
A tree of depth 254 means 254 hashes per membership proof. Each nullifier insertion requires a non-membership check followed by an insertion—two trips from leaf to root. This results in hashes per insertion. Since the tree is sparse, insertions are random and must be sequential, so hash count scales linearly with nullifier count. This causes constraint counts in rollup circuits to grow rapidly, leading to long proving times.
Indexed Merkle Tree Constructions
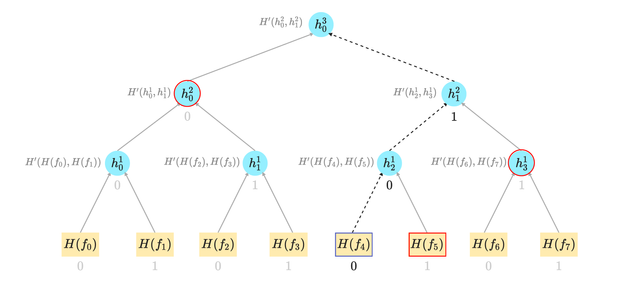
This paper (page 6) introduces indexed merkle trees, which enable efficient non-membership proofs. Each node stores a value and pointers to the leaf with the next higher value:
Based on the tree's insertion rules, no leaves exist between the range .
The merkle tree forms a linked list of increasing values. Once inserted, a leaf's pointers can change but its nullifier value cannot.
Since leaves are no longer positioned at , a deep tree is unnecessary—32 levels suffice. This improves insertions by approximately 8x .
The node that provides the non-membership check is called a "low nullifier".
The insertion protocol:
-
Look for a nullifier's corresponding low_nullifier where:
if is the largest use the leaf:
-
Perform membership check of the low nullifier.
-
Perform a range check on the low nullifier's value and next_value fields:
-
Update the low nullifier pointers
-
Perform insertion of new updated low nullifier (yields new root)
-
Update pointers on new leaf. Note: low_nullifier is from before update in step 4
- Perform insertion of new leaf (yields new root)
Insertion constraints
3nhashes of 2 field elements (wherenis the height of the tree)3hashes of 3 field elements2range checks- A handful of equality constraints
Special cases
At step 3, can be 0. When a value is the maximum, it points to zero instead of a larger value (which does not exist). This closes the loop so insertions always occur within a ring, preventing splits.
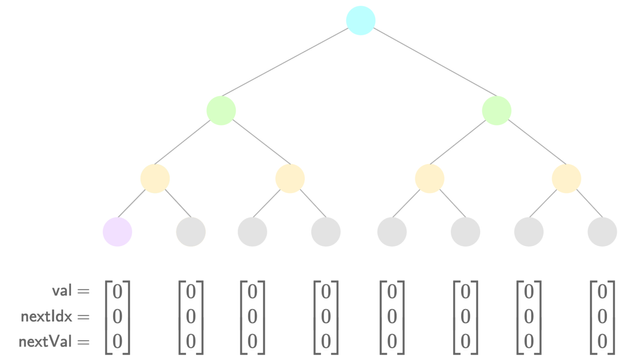
Insertion example
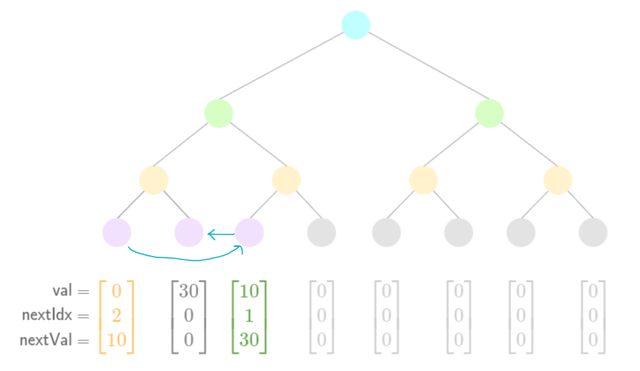
- Initial state
- Add a new value
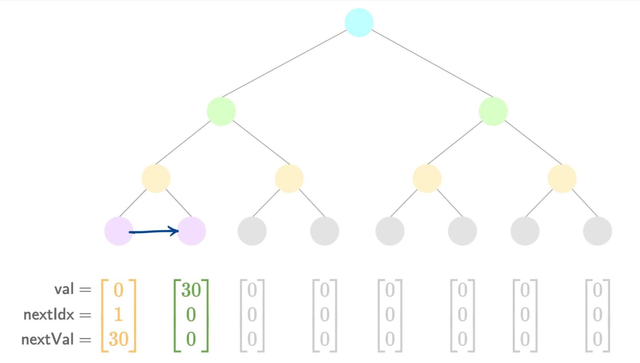
- Add a new value
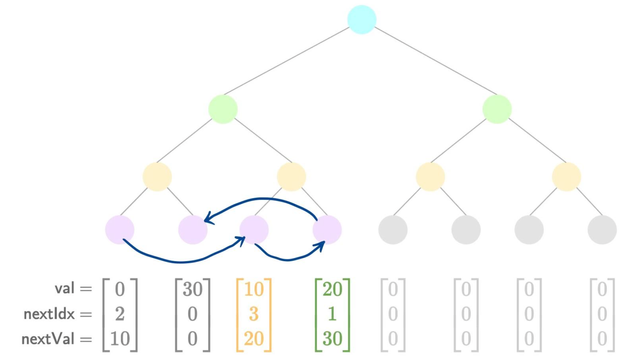
- Add a new value
- Add a new value
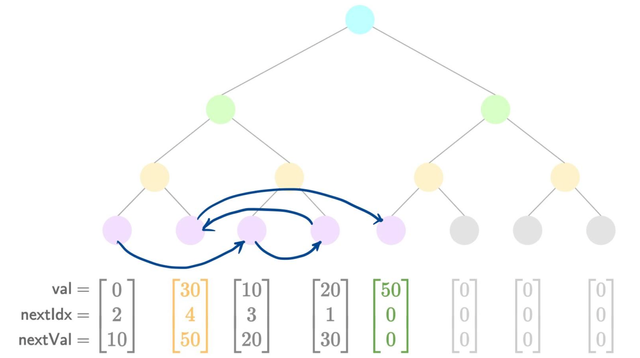
The diagrams show how pointers update between each insertion.
Note: The first node (value 0) is pre-populated, so the first insertion goes into the second index.
Non-membership proof
To prove value 20 does not exist, reveal the leaf that "steps over" 20—the leaf whose value is less than 20 and whose next value is greater than 20. This is the low_nullifier.
- Hash the low nullifier:
- Prove the low leaf exists in the tree:
nhashes - Check the new value would have belonged in the range given by the low leaf:
2range checks- If ():
- Special case, the low leaf is at the very end, so the new_value must be higher than all values in the tree:
- Else:
- If ():
This provides significant performance improvement, but since the tree is not sparse, we can also perform batch insertions.
Batch insertions
Since nullifiers are inserted deterministically (append-only), we can insert entire subtrees rather than appending nodes individually. However, for every node inserted, low nullifier pointers must be updated. This adds complexity when the low nullifier exists within the subtree being inserted. All impacted low nullifiers must be updated before the subtree insertion.
Batch insertion in an append-only merkle tree:
- Prove the target subtree consists of all empty values
- Calculate the root of an empty subtree and perform an inclusion proof for this empty root
- Recreate the subtree within the circuit
- Use the same sibling path to get the new root after subtree insertion
In the following example, a subtree of size 4 is inserted. The subtree is greyed out as "pending".
Legend:
- Green: New Inserted Value
- Orange: Low Nullifier
Example
- Prepare to insert subtree
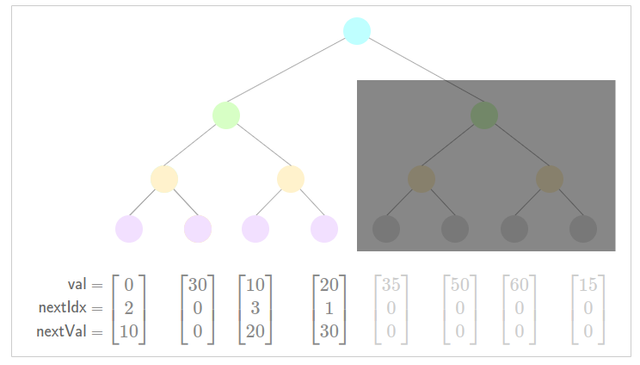
- Update low nullifier for new nullifier
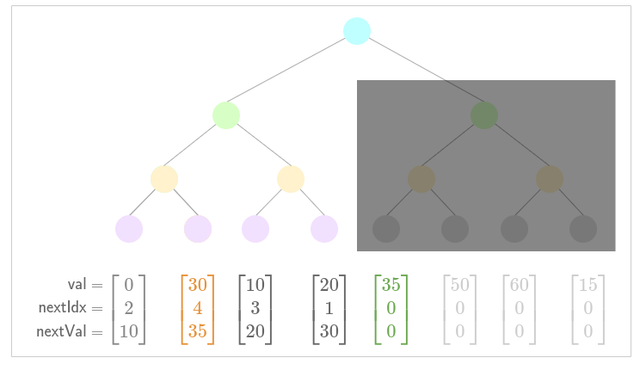
- Update low nullifier for new nullifier (the low nullifier exists within the pending insertion subtree)
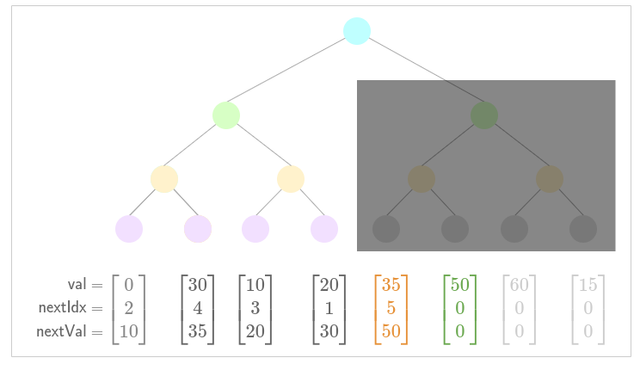
- Update low nullifier for new nullifier
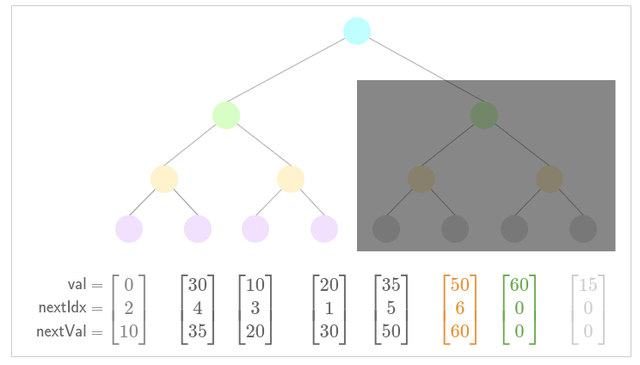
- Update low nullifier for new nullifier
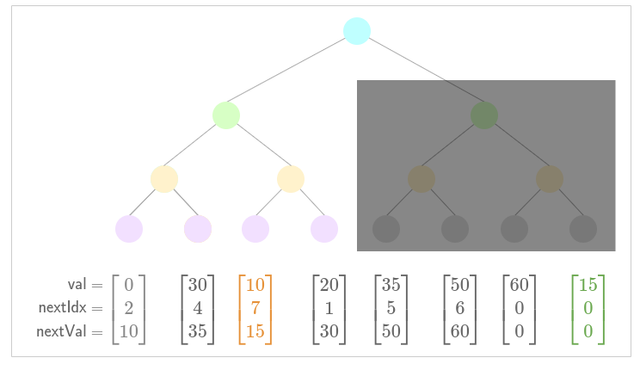
- Update pointers for new nullifier
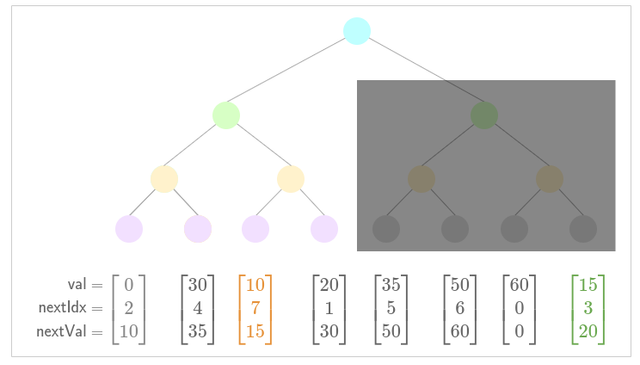
- Insert subtree
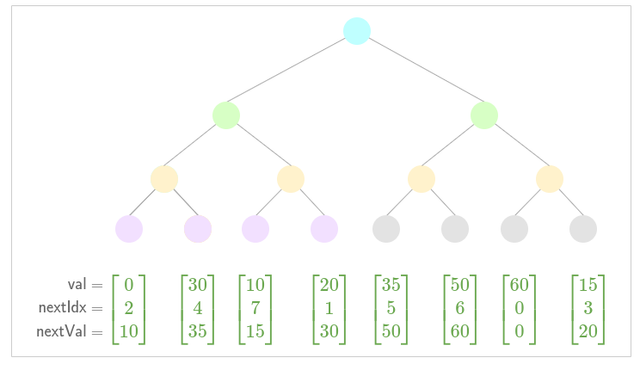
Performance gains from subtree insertion
Sparse nullifier tree insertions require 1 non-membership check (254 hashes) and 1 insertion (254 hashes). For 4 values: 2032 hashes.
In a depth-32 indexed tree, each subtree insertion costs 1 non-membership check (32 hashes) and 1 pointer update (32 hashes) per value, plus subtree construction (~67 hashes). Total: 327 hashes—a significant efficiency gain.
Range check constraint costs are negligible compared to hash costs.
Performing subtree insertions in a circuit context
A challenge arises when the low nullifier for a value exists within the subtree being inserted. In this case, you cannot perform a non-membership check against the tree root because the leaf needed for non-membership has not yet been inserted. These are called "pending" insertions.
Circuit Inputs
new_nullifiers:fr[]low_nullifier_leaf_preimages:tuple of {value: fr, next_index: fr, next_value: fr}low_nullifier_membership_witnesses: A sibling path and a leaf index of low nullifiercurrent_nullifier_tree_root: Current root of the nullifier treenext_insertion_index:fr, the tip of the nullifier treesubtree_insertion_sibling_path: A sibling path to check the subtree against the root
If the low nullifier does not yet exist in the tree, membership checks fail and no non-membership proof can be produced. To handle this, the circuit must track all values pending insertion:
- If
low_nullifier_membership_witnessis invalid (all zeros or leaf index of -1), this indicates a pending low nullifier read request - Loop through all pending insertions to find one with value lower than the nullifier being inserted
- If no matching pending insertion is found, the circuit is invalid
Pseudocode with pending insertion handling:
auto empty_subtree_hash = SOME_CONSTANT_EMPTY_SUBTREE;
auto pending_insertion_subtree = [];
auto insertion_index = inputs.next_insertion_index;
auto root = inputs.current_nullifier_tree_root;
// Check nothing exists where we would insert our subtree
assert(membership_check(root, empty_subtree_hash, insertion_index >> subtree_depth, inputs.subtree_insertion_sibling_path));
for (i in len(new_nullifiers)) {
auto new_nullifier = inputs.new_nullifiers[i];
auto low_nullifier_leaf_preimage = inputs.low_nullifier_leaf_preimages[i];
auto low_nullifier_membership_witness = inputs.low_nullifier_membership_witnesses[i];
if (low_nullifier_membership_witness is garbage) {
bool matched = false;
// Search for the low nullifier within our pending insertion subtree
for (j in range(0, i)) {
auto pending_nullifier = pending_insertion_subtree[j];
if (pending_nullifier.is_garbage()) continue;
if (pending_nullifier[j].value < new_nullifier && (pending_nullifier[j].next_value > new_nullifier || pending_nullifier[j].next_value == 0)) {
// Found matching low nullifier
matched = true;
// Update pointers
auto new_nullifier_leaf = {
.value = new_nullifier,
.next_index = pending_nullifier.next_index,
.next_value = pending_nullifier.next_value
}
// Update pending subtree
pending_nullifier.next_index = insertion_index;
pending_nullifier.next_value = new_nullifier;
pending_insertion_subtree.push(new_nullifier_leaf);
break;
}
}
// could not find a matching low nullifier in the pending insertion subtree
assert(matched);
} else {
// Membership check for low nullifier
assert(perform_membership_check(root, hash(low_nullifier_leaf_preimage), low_nullifier_membership_witness));
// Range check low nullifier against new nullifier
assert(new_nullifier < low_nullifier_leaf_preimage.next_value || low_nullifier_leaf.next_value == 0);
assert(new_nullifier > low_nullifier_leaf_preimage.value);
// Update new nullifier pointers
auto new_nullifier_leaf = {
.value = new_nullifier,
.next_index = low_nullifier_preimage.next_index,
.next_value = low_nullifier_preimage.next_value
};
// Update low nullifier pointers
low_nullifier_preimage.next_index = next_insertion_index;
low_nullifier_preimage.next_value = new_nullifier;
// Update state vals for next iteration
root = update_low_nullifier(low_nullifier, low_nullifier_membership_witness);
pending_insertion_subtree.push(new_nullifier_leaf);
}
next_insertion_index += 1;
}
// insert subtree
root = insert_subtree(root, inputs.next_insertion_index >> subtree_depth, pending_insertion_subtree);
Drawbacks
While indexed merkle trees provide significant circuit performance improvements, they increase computation and storage requirements for nodes. Finding the "low nullifier" for a non-membership proof requires searching existing nodes—a naive implementation uses brute force. Performance improves if nodes maintain a sorted data structure of existing nullifiers, though this increases storage footprint.
Related resources
- State Management - How public and private state work, including nullifiers
- Circuits - Core protocol circuits where indexed merkle trees are used
- Note Discovery - How private notes are discovered and managed
- Original paper - Academic reference for indexed merkle trees